|
|
Vol.
35 No. 4
July-August 2013
by Bonnie Lawlor
Since the launch of the first scientific and scholarly journals in 1665 (Journal des Sçavans and Philosophical Transactions), the amount of scientific information has continued to grow exponentially. It was estimated that 50 million scholarly articles had been published between 1665, when the Journal des Sçavans was first published, and the close of 2009, when the annual article output was estimated at 1 504 600.1 How can these articles and the data they contain be mined to extract new information and advance scientific and scholarly research? To answer this question, a group of researchers, publishers, librarians, and technologists gathered for the National Federation of Advanced Information Services’ conference In Search of Answers: Unlocking New Value from Content, held 24–26 February 2013 in Philadelphia, Pennsylvania, USA. The purpose was to highlight examples of how the application of technologies such as data mining, linking, analytics, and metrics can expose, enhance, and create new information and insights from data already at hand.
The opening keynote given by David Weinberger, senior researcher at the Berkman Center for Internet and Society and co-director of the Harvard Library Innovation Lab, set the stage for the meeting with a perspective on what it means to “know” in an era marked by an exponential growth of digital information and the emergence of multimedia data formats that are appearing with increasing frequency in e-journals. He stressed the importance of linked data and collaborative networks in the development of knowledge. Citing the difficulty in reaching scientific conclusions in the face of a constant stream of new data, he stressed the value of aggregating large, diverse datasets in order to unearth new “facts,” both as an individual scientist, but better yet, in collaboration with other experts. Provocatively, he put forth the following question: If through data mining a new equation emerged that accurately predicted outcomes, but the “why” of the equation’s accuracy was not understood, should that equation be considered invalid even if nothing exists to take its place? His point was that in some cases, predictable, actionable results can carry more weight than the “why” of the results, especially in an era of Big Data and the tools with which to dissect and analyze that data (this position is emphatically reinforced with examples in a new book entitled Big Data: A Revolution that will Transform How We Live, Work and Think by Viktor Mayer-Schönberger and Kenneth Cukier).
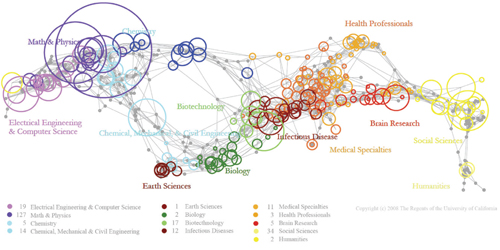 |
| An example of a Big Data visualization presented by Timothy Hitchcock. This UCSD Map of Science, created by information scientists Angela M. Zoss and Katy Börner, gives job information based on scientific discipline (Katy Börner, "Plug-and-Play Macroscopes," Communications of the ACM, Vol. 54 No. 3, Pages 60-6910.1145/1897852.1897871). Reproduced with permission. |
Weinberger was followed by the session “In Search of Answers: Scientists and Scholars Speak Out.” In this session, researchers talked about their own initiatives, all of which were undertaken to create new knowledge and insights from existing content. Timothy Hitchcock, a professor at the University of Hertfordshire, UK, discussed his work in using text mining to uncover unexpected relationships and trends on a variety of topics in the humanities. Funded by JISC, a team downloaded and analyzed 127 million words of text that were extracted from the trials that form The Proceedings of the Old Bailey (1674–1913). Using the Mathematica 8 software, the full-run of 197 000 recorded trials was examined. As a result, their work showed how accounts of trials evolved between the late seventeenth and early twentieth centuries. And an unexpected find of their study was that the accepted narrative of the evolution of the criminal trial was wrong, and that the rise of “plea bargaining” in the 19th century was a significant development in shaping the modern criminal justice system. Hitchcock stressed the importance of combining Big Data with statistical analyses and visualization as a means of simultaneously unearthing both macroscopic and microscopic patterns. He said that these tools will shape the future of scholarship and research across all disciplines.
Hitchcock’s comments were reinforced by other speakers throughout the conference. John Coleman, director of the Phonetics Laboratory, Oxford University, UK, also focused on data mining, but the data was the spoken word–not text (about 9 000 hours, 100 million words, or 2 Terabytes of speech)–the largest phonetics study ever undertaken. He pointed out that speech represents the largest electronic flow of information (4 billion Gigabytes/year) and that the goal of their project is to make large-scale audio files readily accessible and easily usable for researchers (e.g., relevant video clips and data describing taped experiments, speeches, etc.). Although the research is ongoing, the group has already developed and distributed tools for transcribing audio, for checking transcriptions, and for aligning the transcriptions with audio recordings. They are developing tools for interactive search and display of audio/transcript combinations and plan to create tools for indexing and searching phonetic transcriptions with interfaces to tools for visualization and statistical analyses.
Alberto Pepe, information scientist at the Center for Astrophysics, Harvard University, spoke on the ADS All-Sky-Survey, a major project with the objective of transforming the NASA Astrophysics Data System (ADS) from a literature resource to one that is also a data resource. ADS is the most accurate and complete record of published research in astrophysics, with papers ranging from the late 1700s through the present. All of the data (images, tables, object references) contained in these articles is being “astro-tagged” so that the data itself can be searched and analyzed while links to the original research, as well as to the relevant objects in the sky, are maintained. One outcome is a fascinating all-sky map in which published literature is overlaid on the sky. When viewed over time (pre–1900s to present) one can look at the “sky” and visualize what areas have been written about and when, link to the article to learn why, and ultimately identify what areas may be ripe for research. The map is expected to go live this year.
One of the most intriguing presentations was made by Larry Birnbaum, chief scientific advisor at Narrative Science, a company that grew out of work started in the computer science department at Northwestern University in Evanston Illinois. They have developed software and a set of statistical analytic tools that actually generate insightful text from raw data and charts. While many examples were based upon reams of financial data, they also are working with pharmaceutical companies to generate meaningful and timely actionable reports from clinical trial data. They are able to generate human-quality narratives from Big Data at machine speed and scale and provide companies with the ability to make better and faster decisions.
Christopher Burghardt, vice president of product and market strategy at Thomson Reuters IP & Science, spoke about data and nontraditional content from the perspective of current challenges to creating, finding, using, and citing such information. Many researchers do not want to publish data if they do not receive credit. His organization surveyed 417 researchers and found that only 16 percent believe they are receiving adequate recognition for publishing their data, 62 percent would publish more if they received credit, and 66 percent believe it is important/very important for them to get credit for publishing data independently from the credit they receive for their traditional journal articles. He noted that researchers deposit their data in a variety of locations: 51 percent on their personal websites, 47 percent in their department or institutional repository, 36 percent with third parties, 24 percent with publishers, and 17 percent with other sources. With more than 500 credible repositories around the globe (see http://databib.org/), it is not always easy to find data that is available. Burghardt discussed the Data Citation Index that was recently launched to facilitate data discovery, measure its use and re-use, provide standards for attribution, and promote new metrics for digital scholarship.
After hearing about new content generated as a result of applying text mining and statistical analysis to existing information, the discussion turned to new tools that have emerged for measuring the value of scientific output. Andrea Michalek, co-founder of Plum Analytics, talked about metrics beyond the traditional bibliographic citation—a genre of metrics categorized as altmetrics. She noted that citation counts are not an immediate indicator of important research because it takes three to five years for research to receive a critical mass of citations. She also pointed out that informal forms of influence (e.g., blogs, news stories, downloads, etc.) are not cited and that as a result only 30 percent of items that demonstrate the value of research are actually used to highlight its impact. Her organization captures five different impact categories–usage (downloads, views), captures (saves, favorites), mentions (news, reviews), social media (shares, likes, tweets), and traditional citations (Web of Science, Scopus, Google Scholar, patents, etc.). They are able to merge the results from diverse sources and provide researchers and organizations with a snapshot of their research’s impact. She emphasized that true value and relevance of research can only be measured by the combination of immediacy and citation impact.
Michalek’s position was reinforced by Jason Priem, a doctoral student at the University of North Carolina, Chapel Hill. Priem stated that citations only tell a part of the story, quoting Thomas Kuhn, noted physicist turned historian, who said that spotting emerging research fronts will require tracking both “formal and informal communication.” He mentioned the same types of informal “influencers” as did Michalek–discussions, saves, views, recommendations, shares, and citations. With the support of the Alfred P. Sloan Foundation, the National Science Foundation, Dryad, and others, Priem has co-founded another source of altmetrics, Impact Story. This is an open-source, web-based tool that helps researchers explore and share the diverse impacts of all their research products–traditional ones like journal articles, but also alternative products like blog posts, datasets, and software. It is also used by funding organizations who want to see what impacts they might be missing if they only consider citations to journal articles and patents.
At the end of the session on metrics the audience was asked if they agreed that new metrics are needed to measure the value of scholarly output due to the changes in scholarly communication that have resulted from collaborative research, open access, use of social media, and interactive communication. Using audience response devices, 53 percent strongly agreed and 42 percent agreed. When asked if the new metrics would replace or complement the traditional citations, the votes tallied with 91 percent saying that altmetrics will complement citations, 7 percent saying that they will replace citations, and the remainder having no opinion.
 |
| IBM's Watson computer system competes against Jeopardy!'s two most successful and celebrated contestants —Ken Jennings (left) and Brad Rutter. Source: IBM. |
The conference closed with an attempt to answer the following question: Can the transformation of the world’s cumulative content and data truly be transformed into knowledge? This was done taking a look at the role that artificial intelligence, specifically through IBM’s Watson and its progeny, will play in the future. Frank Stein, director of the IBM Analytics Solution Center, noted that according to the International Data Corporation, the amount of information in the world is now doubling every two years and he questioned how we can ever turn that data into insights and knowledge. IBM took on the challenge to design a computing system that would rival a human’s ability to answer questions posed in natural language, interpret meaning and context, and retrieve, analyze, and understand vast amounts of information in real time. Their first objective was to be able to answer questions in competition with humans on the popular TV show, Jeopardy. They started development in 2007 and by the fall of 2010 they believed that the new system, Watson, was ready. Key to their task was developing an algorithm that could not only parse a sentence, but also understand it. He used the following sentence as an example: “If leadership is an art then surely Jack Welch has proved himself a master painter during his tenure at General Electric (GE).” Could a computer deduce from this sentence that Jack Welch was the CEO at GE? Ultimately, it could. To get the results IBM acquired as much diverse information as possible and applied natural language processing, information management, machine learning, and distributed computing with massively parallel processing. They used 90 high-powered servers and 10 refrigerator-sized racks for the machine. And they proved that Watson could win over the two previous biggest winners on Jeopardy. As a result, Watson captured the imagination of a wide audience.
Since then, IBM has made many enhancements to make the system practical in the real world. It is now 240 percent faster, only requires one rack of equipment, and can accept multi-dimensional input. Health care is their first area of interest. He pointed out that there are 95 new clinical trials launched every day and that medical information, much of which is unstructured, is doubling every five years. Yet, 81 percent of physicians report that they spend five hours or less per month reading medical journals! This is an area in which Watson can play a significant role. Their first product launch is in collaboration with the Sloan Kettering Clinic and will be focused on cancer treatments–specifically lung, breast, prostate, and colorectal cancers. They are also in discussions with organizations both in the financial and scientific arenas. Stein closed by saying that we are now in an era of being able to build knowledge through cognitive computing.
Everyone at the conference agreed that the combination of Big Data and technology is a major catalyst in the advancement of research and knowledge. To quote the authors of the book mentioned earlier in this report, “. . . the new techniques for collecting and analyzing huge bodies of data will help us make sense of our world in ways we are just starting to appreciate.”
http://nfais.org/event?eventID=399
1. Jinha, Arif E., "Article 50 Million: an estimate of the number of scholarly articles in existence," Learned Publishing, Vol. 23, No. 3, July 2010.
Page
last modified 29 August 2013.
Copyright © 2003-2013 International Union of Pure and Applied Chemistry.
Questions regarding the website, please contact [email protected]
|



