![]()
>Vice
President's Column
>XML
in Chemistry
>A
Preprint Server for Chemistry
>IUPAC
Forum
>IUPAC
News
>IUPAC
Projects
>Highlights
from PAC
>Provisional
Recommendations
>New
Books
>Reports
from Conferences
>On
the web
>Conference
Announcements
>Conference
Calendar
Chemistry International
Vol. 24, No. 4
July 2002
In the Maze of XML
Crystallographic Information File
XML in Chemistry?
How Well Are We Using XML in Chemistry?
by Jonathan GoodmanFrom an academic and educational viewpoint, one could say, unfortunately, not too well right now. Here are some reasons. One of the reasons is the complexity of XML. It may well be as simple as it can be, but it is not simple, and it requires substantial effort to master the syntax and restrictions of its structure. For example, <xsl:number count="paragraph" format="а"> is an instruction to number paragraphs in old Slavic, a powerful feature, but probably not frequently used, nor immediately comprehensible to the casual reader. Despite its complexity, the structure of XML relates well to the thought processes of most chemists and to the process of using marked-up text. For example, entering a name in the author search box of the World of Science, or other chemical database, is becoming so obvious as to require almost no thought. It could be suggested that, even though the details of XML syntax are not widely known, the structure that it imposes on documents is both understood and expected.
Successful Examples
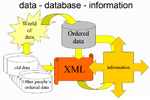
A number of databases have been developed in our research group and made available on the Web. The general process we have followed is first to gather data from the huge and disordered sources and put them in an ordered and focused form. We then take this collection and find a way of presenting it so that it is useful information. For example, we have explored the Web for university chemistry departments, collected their URLs and names in text files, which we do not make available, and used these text files to create HTML and Java programs, which can be queried through the Internet. This final product is valuable information and it is created by a two-step process: order information and then present it. The database is available at <www.ch.cam.ac.uk/c2k/>.
We could introduce another step into the process: ordered information to XML before creating the simplified and beautified form, which is then made available. However, this extra step requires additional effort, which brings no immediate benefit. The potential of the XML form in chemistry is that it could relate well to other people's XML data and to old data from related projects in the group. However, this stage is an advantage for the future, and not the present, unless a clear community consensus is to recognize the preferred structure of XML for chemists; then, this extra step should become worthwhile.
While marking-up, ordering, and sharing data, one success of our department is our list of colloquia. Six different subject-groups within the department regularly invite external speakers to give lectures, while many other lectures are arranged on a less predictable basis. How can all of this information be put in a consistent form and used effectively to produce current information and a searchable and logical archive? The information comes from a wide variety of people, who usually run the colloquium program for only a short time before handing the responsibility on. The entire process achieves the unification of disparate information. Today's lectures are available on the Web at <www.ch.cam.ac.uk/today/>, a page that is automatically updated. Historical lists and current lists of lectures are available in a consistent format. Information is flowing freely and available to be used and reused in different ways, both automatically and by individuals. A restricted subset of HTML is used to order the information. The restrictions mean it could easily be converted by computer to a pure XML form. This is a successful datahandling project in chemistry, which has not been a trivial problem to solve. However, it is much simpler than the more general issues of chemical information.
Lecture handouts are also shared well, not because they are produced in a consistent and reusable form, but because of the high standard of our undergraduates' ability and industry. Exam papers also work effectively, because a very precise format is required and enforced. We do not have the option of turning to another publisher who might be more relaxed about presentation and the precise way in which diagrams are constructed. Compound databases and experimental data are shared much less effectively, even within the department of chemistry, and the situation gets worse when communication is attempted with other departments.
Conclusion
There is a long way to go before XML is used routinely to improve and enhance chemical communication. However, XML friendly structures are already in place, and this should mean that a lot of data can easily be moved to this marked-up language. If an XML-based standard is accepted, then this process could be very rapid and data could be shared and reused much more easily than is now possible.
Jonathan Goodman <[email protected]> is a Professor in the Department of Chemistry, Lensfield Road, Cambridge, United Kingdom.


![]()
News
and Notices - Organizations and People
- Standing Committees
Divisions
- Projects - Reports
- Publications - Symposia
- AMP - Links
Page last modified 27 June 2002.
Copyright © 1997-2002 International Union of Pure and Applied Chemistry.
Questions or comments about IUPAC, please
contact the Secretariat.
Questions regarding the website, please contact [email protected]